稍长,多个几分钟吧...
The URL interface is used to parse, construct, normalize, and encode URLs.
对 URLs 即网络地址或链接解析、构造、规范化、编码
简单说对页面地址,比如 https://baidu.com 通过 URL 构建解析,变成易编程的格式
# 用法
URL 为内置全局构造函数,通过 new URL 使用,参考为字符串或url对象
const url = 'https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9575152475594390165%22%7D&n_type=0&p_from=1#a=1'
const urlIns = new URL(url) // 对象结构如下
/*
hash: "#a=1" => 包括 #
host: "mbd.baidu.com"
hostname: "mbd.baidu.com"
href: "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9575152475594390165%22%7D&n_type=0&p_from=1#a=1"
origin: "https://mbd.baidu.com"
password: ""
pathname: "/newspage/data/landingsuper" => '/' 开头的路径
port: ""
protocol: "https:" => 包括 :
search: "?context=%7B%22nid%22%3A%22news_9575152475594390165%22%7D&n_type=0&p_from=1" => 包括 ?
searchParams: URLSearchParams {}
username: ""
*/
urlIns.host // 查看服务器名称
urlIns.href // 查看完整地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
大部分属性与 window.location 对象重合,location 结构如下:
ancestorOrigins: DOMStringList {length: 0}
assign: ƒ assign()
fragmentDirective: FragmentDirective {}
hash: "#a=1"
host: "mbd.baidu.com"
hostname: "mbd.baidu.com"
href: "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9575152475594390165%22%7D&n_type=0&p_from=1#a=1"
origin: "https://mbd.baidu.com"
pathname: "/newspage/data/landingsuper"
port: ""
protocol: "https:"
reload: ƒ reload()
replace: ƒ replace()
search: "?context=%7B%22nid%22%3A%22news_9575152475594390165%22%7D&n_type=0&p_from=1"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
URL 方法相对 window.location 对比来看,好像也没太大优势。
并不是,location 为 BOM 对象,在浏览器中才可以访问到,Node 环境下是访问不到。
URL 并不是,ECMAScript 对象,与运行环境无关
两者都可以对其属性进行修改,不同之外在于,前者修改不会刷新页面,后者会。
修改 hash 除外
const url = 'https://baidu.com#test'
const urlIns = new URL(url)
urlIns.protocol // https:
urlIns.protocol = 'http' // 当前页面并不会重载刷新,如果使用 location 则会,可自行测试下
urlIns.protocol // http:
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
另外,最大的优点:
URL 实例的 searchParams 对象可对查询参数 search 解析并提供 get、delete 等操作方法
const url = 'https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9575152475594390165%22%7D&n_type=0&p_from=1#a=1'
const urlIns = new URL(url)
urlIns.search // ?context=%7B%22nid%22%3A%22news_9575152475594390165%22%7D&n_type=0&p_from=1
// 获取 p_from 内容
urlIns.searchParams.get('p_from') // 1
// location 未提供相关的方法供调用,如果解析需要手动实现
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
urlIns.searchParams 对象是啥 ?为什么能够解析 search ?
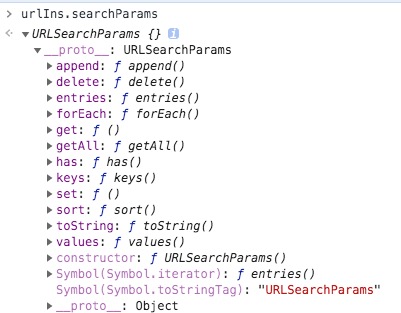
很直观看到继承 URLSearchParams 原型,也就是说
urlIns.searchParams.get === URLSearchParams.prototype.get // true
1
# URLSearchParams 用法
用来处理 URL 查询字符串的,简单地说处理 location.search 部分,
如果是完整的 URL呢?也起作用,结果比较诡异,可通过下面的链接了解详情
const url = 'https://baidu.com/search?foo=1&bar=2&foo=3' // 查询参数可以重复
const ins = new URLSearchParams(url)
ins.has('foo') // false
ins.get('foo') // null
// search 部分
const search = new URL(url).search // ?foo=1&bar=2
const ins2 = new URLSearchParams(search)
ins2.has('bar') // true
ins2.get('bar') // 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
其他的方法:
append(key, value) 插入查询参数,可以重复
set(key, value) 设置查询参数,删除重复值,保留最新的设置值
delete(key) 删除某个查询参数,包括重复
sort() // 按字母序排序查询参数
getAll(key) // 获取所有同名的键值
get(key) // 只获取一个键值,区别 getAll 获取所有
# 因为 `new URLSearchParams` 返回是 `iterator` 遍历器对象,所以还有遍历方法
keys() // 遍历键名
values() // 遍历键值
entries() // 遍历键值对
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
URLSearchParams 使用详情 » (opens new window)
# 兼容性
URL 与 URLSearchParams 兼容性良好,可用于移动端开发
扫一扫,微信中打开
